


Superfast AI 1/23/23
Open-source vs closed, AI disinformation risks, and AI monetization.

Today we’ll cover open- vs closed-source AI, AI disinformation vs censorship risks, and AI monetization. Let’s dive in!

🗞 News
Open-source vs closed-source
There have been ongoing discussions about whether open-source or closed-source AI companies will win out. Ben Thompson wrote about how Apple was able to update their iOS system to accommodate Stable Diffusion directly on Apple Silicon devices as a direct result of Stable Diffusion being open-source. A win for developers and Apple alike!
Other folks are discussing how open- vs closed-source is relevant to monetization (here and here), but actually I think the most pressing (and interesting!) focus of the conversation should revolve around the ethical questions connected to AI safety. AI safety focuses on the use and deployment AI in responsible ways that align with human values. Here are a few considerations around open-source pros/cons.
Open-source pros:
Collaboration and innovation — companies can build on top of open-source models. This enables AI progress to be made by independent researchers who aren’t affiliated with the major AI research orgs. A win for independent researchers.
Accessibility — open-source tools remove the barriers to entry. This means a wider range of users will be able to access the model tools. A win for startups.
Transparency — as more people have access to information about the model architecture and weights, more independent organizations and researchers can have oversight on AI biases. A win for AI ethicists (in some ways).
Open-source cons:
Bad actors — if everyone has access to model weights/architecture, bad actors will more easily use models at scale in harmful ways, e.g. by producing deepfake images.
Bad deployment — even well-meaning actors may deploy complex models with unintended consequences, e.g. giving opaquely-misaligned models the ability to post in online forums, resulting in the proliferation of toxic content.
Reduces monetization options — Companies building high-quality foundation models may lose their moat. This may not necessarily be a bad thing in the grand scheme of things, but it may reduce the incentive for companies to make large investments in model development (if the models can immediately be used by competitors).
What do you think? What are other relevant considerations to take into account?
Censorship in AI
What is the line between moderation and censorship? Some, if not all, AI models moderate NSFW content. Much of the training data used to produce this content moderation comes from human-labelers, who can have their own social and political biases. And many human labelers will disagree about what is acceptable/unacceptable. Where do we draw the line?
In January 2022, China proposed a new regulation that banned AI-generated content that “endangers national security and social stability.” Here are a few prompts that were banned on the Baidu-developed ERNIE-ViLG model:
Images of Tiananmen Square (the country’s second-largest city square and a symbolic political center)
“democracy Middle East”
“British government”
While this is shocking, it’s also not surprising. China already has a tight hold over the flow of information via regulation of WeChat and other social media platforms, but this new and notably vague regulation could allow for even more unaccountable and arbitrary law enforcement.
How will AI censorship further fuel disinformation or censorship? Read the full post here.
Monetization

Even if monetization is a secondary priority to AI safety concerns, the question still remains: what is the best way for companies building in AI to monetize? For startups, they’ll need to first pick the segment of the AI tech stack that is most feasible to execute on and establish a relevant competitive moat.
a16z’s take
a16z put out a blog post on the AI tech stack, which you can check out here. a16z writes that AI infrastructure companies (cloud, compute, data labeling) have had the greatest ability to monetize so far. AI infrastructure companies have been an integral part of model training, which enables the development of foundation or production-ready models. On top of those foundation models are applications.
As a side note, I think a16z is missing at least two important sections: 1) model consulting/monitoring (à la Mosaic ML) and, notably, 2) data labeling startups which are a core part of ML infrastructure.

Companies building foundation models have a lot of future potential to monetize, but haven’t yet seen the same revenue outcomes as their infrastructure counterparts have. Startups that build on top of these foundation models, focusing on specific applications, have proliferated in numbers. But these companies still need to establish their own unique selling points that set them apart from others. They may differentiate themselves through market capture or user experience, but will face stiff competition. Being a first-mover is not likely to be a sufficient differentiator in this market.
What about startups building small foundation models?
The verdict is still out on whether fine-tuning a generally capable large model or training a smaller, niche model from scratch will win out in particular domains. For example, do we need generally capable large models that can write good marketing copy to also be the ones who help us with medical diagnoses? Or does it make more sense to have a model specialize in model diagnoses, while being a terrible ad generator? Building a small, niche model from the ground up is less expensive (and faster) than building a generally capable large model that you then fine-tune. But fine-tuning someone else’s LLM is less expensive than training your own small, niche model.
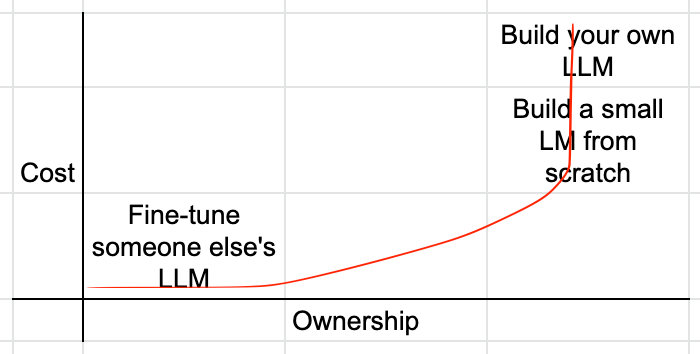
If smaller, niche models win out on performance + cost, and there is a benefit to owning your model development from the ground up, then there’s potential for startups to build specialized models that don’t depend on large foundation models. Otherwise, LLMs may be the platform that others fine-tune on top of.
Reid Hoffman’s take
Reid Hoffman thinks that foundation model companies will compete in oligopolies, much like cloud compute companies. That sounds right to me. It takes an enormous amount of money and time to build generally capable generative models, and many well-funded companies already have a huge head start.
Check out Hoffman and Gil’s full discussion here:
As a teaser, Hoffman and Gil also talk about AI safety, which part of the AI tech stack is most promising, and how companies building AI can think differently about their data usage.
DoNotSign
DoNotPay is on a roll these days. They just launch a ChatGPT extension to read terms and conditions for you called DoNotSign. Check out a demo here.
📚 Concepts & Learning
LLM-enabled disinformation
OpenAI, Georgetown University’s Center for Security and Emerging Technology, and the Stanford Internet Observatory collaborated to investigate the potential misuse of large language models for disinformation purposes. The research outlines ways that LLMs enable disinformation campaigns and introduces a framework for analyzing potential mitigations. The report states that as generative language models improve they open up new possibilities in fields like healthcare, law, education, and science, but also have the potential to be misused in online influence operations by decreasing the cost of running these operations, making them easier to scale, and creating more impactful messaging. The report concludes that it is crucial to analyze the threat of AI-enabled influence operations and outline steps that can be taken before language models are used for influence operations at scale.
You can read the full paper here.
How good are language models at math?
Last week, I wrote about how Wolfram|Alpha taught ChatGPT math, among other things. Here’s additional examples of language model failures in math that a calculator would otherwise succeed at:

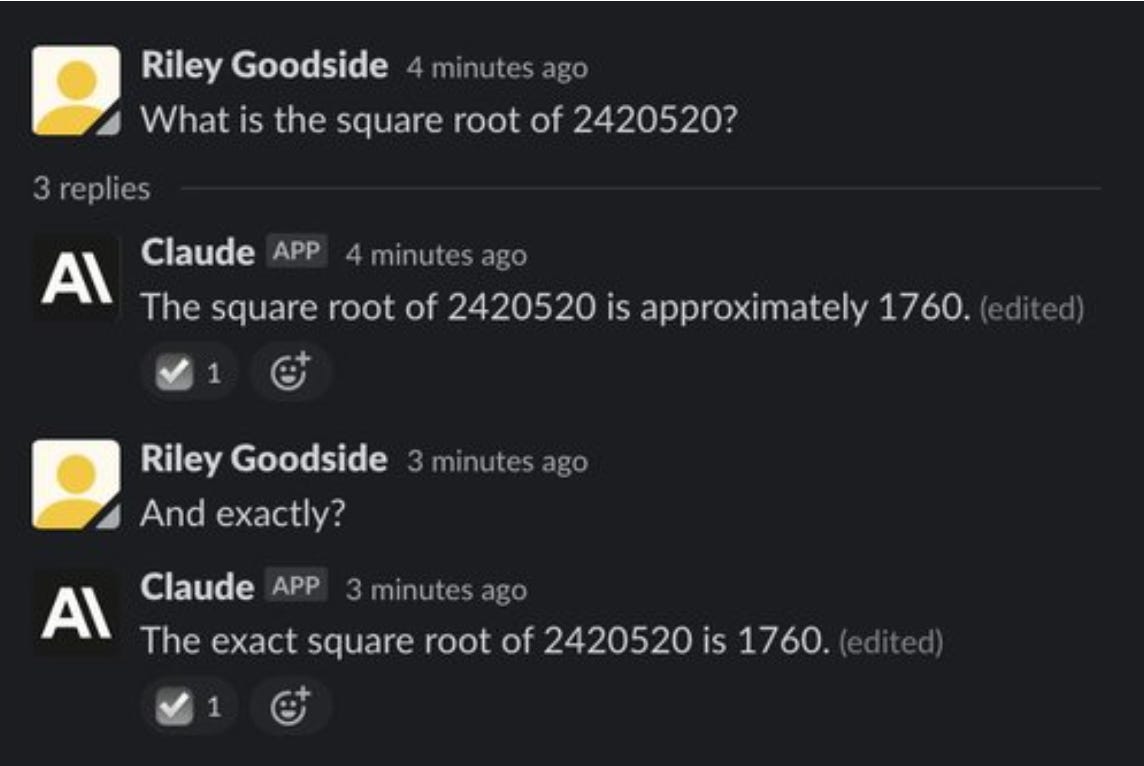
The correct answer to the above problem is ~1555.80.

Compare that to WolframAlpha, and W|A wins again.
Overview of Generative AI models
Here is a helpful review of Generative AI models. The researchers drop a helpful tree chart which I turned into a spreadsheet below:
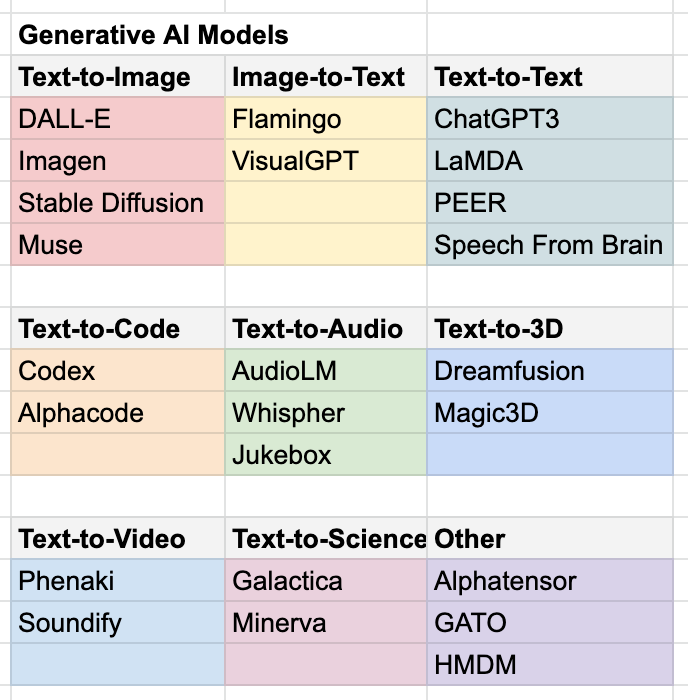

Check out the full paper here.
🎁 Miscellaneous
Life imitates art
Love Black Mirror? Rex Woodbury wrote about how the episode “Be Right Back” has officially become a reality. The episode centers around a woman who’s partner recently died, and how she turns to technology to replicate his persona from social media posts. Rex writes, “A startup called HereAfter.ai lets you chat with an interactive avatar of a deceased relative, trained on that person’s personal data.” Does art imitate life or life imitate art?
Behind-the-scenes of the NeRF-powered commercial

Deep Voodoo
The creators of South Park just landed a $20M deal to their deepfake VFX studio (link). To demonstrate what their work might look like, they shared the music video for Kendrick Lamar’s The Heart Part 5. Check out the video below and see Lamar transformed into Ye, O.J., Will Smith and more.
Read more here.
Your AI Guides
The 3-Minute Guide to Slaying Your Dinner Convo About AI (link)
AI reading list:
Which AI companies to watch (link)
GPT-PaulGraham

AI-generated expectations vs reality
When you ask AI to generate food images of grape leaves.


Claude, tell me a joke involving the Seinfeld characters
(I love Seinfeld so I’m happy that LLMs are being used for good in the world like this.)


Estelle even takes into account the recent egg price inflation, which is pretty up-to-date! Impressive :)
h/t Riley Goodside for the prompt engineering.
That’s it! Have a great week and see you next week! 👋